
함수 오버로딩 (Function Overloading) 본문
함수 오버로딩 (Function Overloading)
함수 오버로딩(function overloading)은 다른 매개 변수를 가진 동일한 이름의 함수를 여러 개 만들 수 있는 C++의 기능이다.
함수 오버로딩을 어디에 쓰는지 주의할 점과 장단점을 알아보자.
예를 들어보면

이 간단한 함수는 두 개의 정수를 더한다.
그러나 두 개의 부동 소수점 숫자를 더해야 하는 경우는 어떻게 해야 할까?
부동 소수점 매개 변수가 정수로 변환될 때 소수 값을 잃게 되므로 위 함수는 적합하지 않다.
이 문제를 해결하는 한 가지 방법은 약간 다른 이름을 여러 함수를 정의하는 것이다.

프로그래머 입장에서 내가 어떤 숫자를 더하고 싶은데
그것이 double 인지 int인지 신경쓰고 싶지 않고 그냥 add라는 함수를 만들고 싶을 수 있다.
이때 들어오는 매개변수는 다른데 수행하는 기능은 비슷한 경우 함수 오버로딩을 사용할 수 있다.
함수 오버로딩을 사용하면 double 매개 변수를 취하는 또 다른 add() 함수를 선언할 수 있다.

이 두 함수는 분명히 매개변수가 다르다.
그런데 기능은 비슷하다.
물론 기능이 완전 판이하게 다른 경우에도 함수 오버로딩을 구현할 수 있다.
하지만 일반적으로는 헷갈리니까 그렇게 사용하지 않는다.

컴파일러가 알아서 보고


int 인지 double인지 알아서 찾아서 컴파일 해준다. 편리하다.
이때 몇 가지 주의사항이 있다.
함수가 서로 같다 다르다는 사실 이름만 갖고 판단하는 것이 아니다.
파라미터 매개변수가 다르면 이름이 같아도 다른 함수처럼 정의를 해버린다.
그리고 그것들 중 매개 변수 타입이 가장 잘 맞는 (주어진 인자와 매개변수가 가장 조합이 좋은) 함수를 찾아서 실행시켜 주는 것이다.

여기서는 입력값으로 들어가는 것이 정수니까
먼저 함수 이름이 add 인 것을 찾고
그중에서 매개 변수가 정수, 정수인 것을 찾아서 이것을 사용하면 좋겠구나 판단하고

여기서는 int add(int x, int y)를 사용하게 되는 것이다.

double에서도 물론 똑같은 과정이 일어난다.
여기서 중요한 점은 add가 두 종류가 있는데 여기서 어느 add를 사용할지는 컴파일할 때 결정이 되어야 한다.
이때 주의사항이 뒤에 파라미터는 바뀌어도 되는데 파라미터가 같은 함수 두 개가 있으면 문제가 생긴다.


이때 return 타입이 다른데 어떻게 두 개가 같은 함수냐고 생각할 수 있다.
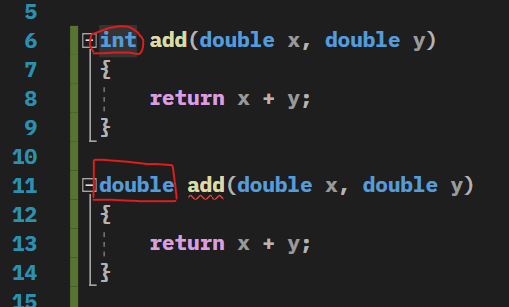
하지만 C++에서는 리턴 타입이 다른 것만 가지고는 함수 오버로딩이 안된다.
매개 변수가 달라야 한다.

만약 이렇게 int가 한 개 더 들어간다면 완전히 다른 함수가 된다.
하지만 리턴타입만 다른 경우에는 오버로딩이 안된다.
Function return types are not considered for uniqueness
함수의 반환 타입은 함수 오버로딩에서 고려되지 않는다.
함수는 인수에만 기반하여 호출된다.
반환 값이 포함된 경우 함수의 어떤 버전이 호출되었는지 쉽게 알 수 있는 구문 방식이 없다.
난수를 반환하는 함수를 작성하려고 하지만
int를 반환하는 버전과 double을 반환하는 다른 버전이 필요한 경우를 생각해보자.
아래와 같이 작성하려 할 수 있다.

하지만 컴파일러는 오류를 발생시킨다.
리턴 값 가지고는 구분이 안되니까 난감해진다.
이럴 때 회피하는 방법은 여러 가지가 있는데
첫 번째 이름을 바꾸는 방법이 있다. (그런데 이건 함수 오버로딩이 아님)

두 번째 방법은
함수 오버로딩에서 함수들을 구분 짓는 것은 매개 변수이니까
하나는 int x 하나는 double x 이렇게 입력을 받도록 해주자라고 할 수 있다.

이때 의문이 드는 것은 입력이 들어가는데 굳이 리턴 값을 받을 필요가 있나? 생각할 수 있다.
앞에 리턴값을 아예 void로 바꿔버리고 참조를 써버리면 된다.

이렇게 매개변수로 값을 돌려받는 방법이 있다.
하지만 이 방법의 단점은 리턴 값을 못 받는다.

값을 이런 식으로 받아야 한다.
얼핏 보면 x가 return으로서 값을 가져오는 건지 입력인지 구분이 잘 안 된다는 것이 단점이다.
Typedefs are not distinct
typedef로 정의했을 때 int를 my_int라고 다른 타입인 것처럼 정의했다고 생각해보자.

typedef 선언은 새로운 타입을 만드는 것이 아니므로 위 print() 함수의 두 선언은 동일하게 간주된다.

이렇게 나오는 것은

그냥 이렇게 된 것과 똑같다.
결국 컴파일러 입장에서 볼 때는 같은 함수가 두 개 있는 꼴이 된 것이다.
이렇게 typedef를 쓰더라도 컴파일러한테 눈속임을 할 수는 없다.
How function calls are matched with overloaded functions
오버로딩된 함수를 호출하면 다음 세 가지 결과 중 하나가 발생한다.
- 일치하는 함수가 있다. (호출이 특정 오버로드된 함수로 해석된다.)
- 일치하는 함수가 없다. (오버로드된 함수 중에 인수가 일치하는 함수가 없다.)
- 모호한 함수가 있다. (하나 이상의 오버로드된 함수와 인수가 일치한다.)
오버로딩된 함수가 호출되면 C++은 다음 프로세스를 통해 호출할 함수의 버전을 결정한다.
첫 번째, 먼저 C++은 정확하게 일치하는 함수를 찾으려고 한다.
이것은 실제 인수가 오버로딩된 함수 중 하나의 매개 변수 타입과 정확하게 일치하는 경우이다.
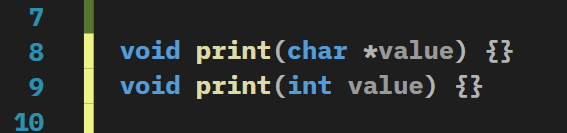

main()에서 print함수에 0을 넣어줬는데
0이 정수이고 정수가 들어가는 함수가 있으니까 정확히

밑에 있는 print (int value)와 일치한다는 것을 알 수 있다.
0은 기술적으로 print(char*)와 일치할 수는 있지만 print(int)와 정확하게 일치한다.
두 번째, 정확히 일치하는 항목이 없으면 C++은 승격(promotion)을 통해 일치하는 함수를 찾으려고 한다.
이것은 암시적 형 변환에서 다룬 적이 있다.
형변환 Type Conversion
암시적 형변환 Implicit Type Conversion(coersion) 즉 컴파일러가 자동으로 하나의 기본 자료형을 다른 자료형으로 변환한다. 자동 형 변환 automatic type conversion 이라고 불린다. 이전에 변수의 값이 일련의
hyoniidaaa.tistory.com
- char, unsigned char, short 가 int로 승격된다.
- unsinged short는 int의 크기에 따라 int 또는 unsigned int로 승격된다.
- float는 double로 승격된다.
- 열거형(enum)은 int로 승격된다.


그런데 여기서는 포인터가 들어가 있다는 것을 주목하자.

위 프로그램의 경우, print(char)가 없으므로 char 'a'는 int로 승격되고 print(int)와 일치한다.
만약 이게 문자열이라면 어떻게 될까?

함수 오버로딩을 잘 쓰면 참 편한데 이런 경우는 조금 난감할 수 있다.
데이터 타입에 대해 주의를 기울여야 한다.
매치를 못 찾을 경우에는 함수가 없다고 나온다.

가장 좋은 방법은 모든 타입에 대해서 깔끔하게 다 정의를 해주고
사용할 때에도 깔끔하게 얘는 int다, 얘는 문자다 등 정리를 잘해주는 것이 좋다.
위 예제 같은 경우에는

이렇게 바꿔주면 깔끔하게 정리가 된다.
왜 이렇게 될까?
char*타입은 문자열 상수를 가리킨다. 즉 변경 불가능하다.
따라서 const(상수) 키워드를 붙였을 때에는 에러가 나지 않는다.
파라미터로 "a"를 해당 함수에게 넘겨주려고 하는데,
"a", "asdsd" 이런 문자열 리터럴은 개발자가 절대 수정할 수 없는, 개발자에게 권한이 없는 영역에 해당하는 메모리에 저장이 된다. 1, 23 이런 숫자 리터럴들도 마찬가지다.
char * ptr = "asdsd"; 이 때문에 이런 일반 char 포인터로 이 문자열 리터럴을 참조해버린다면
언제든지 *ptr 간접 참조를 통하여 이 문자열 리터럴을 수정할 수 있다.
근데 이 문자열 리터럴은 개발자가 절대 수정할 수 없는 영역에 저장되어 있기 때문에 처음부터 문자열 리터럴은
일반 포인터인 char * 에서 참조할 수 없도록 문법적으로 막아두는 것이다.
반면에 const char * ptr = "asdast" 이런 const 포인터는 포인터를 통해 간접 참조로 수정하는 것 자체를 불가능하게 하는 포인터이기에 이 문자열 리터럴 수정을 못하게 막아준다.
그래서 문자열 리터럴을 참조하는 것이 가능한 것이다.
결론적으로 파라미터와 호환이 되지 않으니 오류가 떴던 것이다.
문자열 리터럴은 char * 같은 일반 포인터로 받을 수 없고 const char * 포인터로만 받을 수 있기 때문이다.
여담으로 char ptr[3] = "dd"; 이렇게 배열을 문자열 리터럴로 초기화하는 건 가능한데,
이것도 사실 문자열 리터럴 "dd"의 원본이 있는 수정할 수 없는 그 메모리에서
"dd"를 스택 메모리로 복사해가져와서 그 사본으로 초기화를 하는 것이다.
그래서 배열 원소는 수정 가능한데 이건 사실 문자열 리터럴 원본을 수정하는 게 아닌
개발자가 얼마든지 수정 가능하고 접근할 수 있는 스택메모리에 사본으로서 가져온 걸 수정하는 거라 전혀 문제가 없다.
세 번째, 승격(promotion)이 불가능한 경우 C++은 표준 변환을 통해 일치하는 항목을 찾으려고 한다.
- 숫자 타입은 다른 숫자 타입으로 변환한다. ex) int -> float
- 열거형 enum은 위에서 말한 숫자 공식과 같다. ex) enum- > int -> float
- 0은 포인터 타입 및 숫자 타입과 일치한다. ex) 0 -> char* or 0 -> flaot
- 포인터는 void 포인터와 일치한다.
struct Employee; //defined somewhere else
void print(float value);
void print(Employee value);
print('a') // 'a' converted to match print(float)이 경우 print(char) 및 print(int)가 없으므로 'a'는 float로 변환되어 print(float)과 일치한다.
마지막으로, C++은 사용자 정의 변환을 통해 일치하는 함수를 찾는다.
아직 클래스를 배우지는 않았지만,
클래스는 해당 클래스의 객체와 암시적으로 적용될 수 있는 다른 타입으로 변환을 정의할 수 있다.
예를 들어, 클래스 X의 사용자 정의 변환을 int로 정의할 수 있다.
class X; //with user-defined conversion to int
void print(float value);
void print(int value);
X value; // declare a vatiable named value of type class X
print(value); // value will be converted to an int and matched to print(int)value는 클래스 X 타입이지만 사용자가 정의한 int로 변환하므로 print(value)는 print(int)로 결정된다.
Ambiguous matches
모든 오버로드된 함수가 고유한 매개 변수를 가져야 하는 경우 호출이 둘 이상과 일치하면 어떻게 될까?
예제를 통해 살펴보자

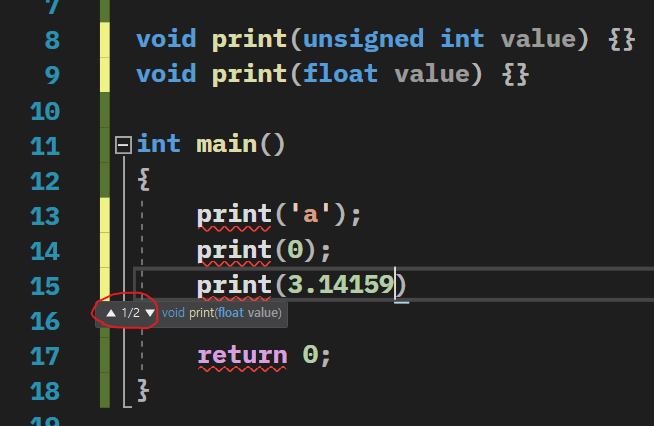
여기서 값을 입력할 때 키보드에서 화살표 방향키를 누르면

오버로딩 된 두 가지 함수를 보여준다.
아무튼 위에서 봤던 경우들에는 잘 맞는 게 없어서 억지로 있는 것들 중에 가장 가까운 것을 끼워 맞췄는데
이번에는 너무 잘 맞는 경우이다.

print('a')의 경우 C++은 정확하게 일치하는 함수를 찾을 수 없다.

'a'를 int로 승격시키려고 하지만 print(int)도 없다.
표준 변환을 하면 'a'는 unsigned int와 float으로 변환할 수 있다.
이 두 표준 변환으로 인해 모호한 일치가 발생한다.
print(0)도 비슷하다.

0은 int이며, print(int)는 없다. 결국, 표준 변환으로 인해 모호한 일치가 발생한다.
print(3.14159)는 조금 놀랍다.

모든 리터럴 부동 소수점 값은 f접미사가 없으면 double이 된다.
3.14159는 double이며 print(double)은 없다.
따라서 표준 변환을 통해 모호한 일치가 발생한다.
정확하게 넣어줄 필요가 있다.
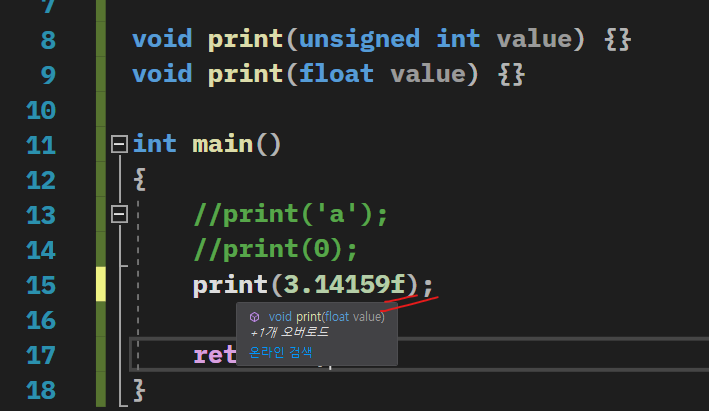
뒤에 f를 붙이면 float가 되고

0 뒤에는 u를 붙이면 unsigned int 가 된다.
a같은 경우에는 char 캐릭터라서 넣을 자리가 없다.
그럴 때는 프로그래머의 의도에 따라서
이런 식으로

아예 캐스팅을 해서 깔끔하게 넣어버리는 방법이 있다.

그러면 이렇게 의도한 대로 명확하게 지도해주면 함수 오버로딩이 모호성을 제거할 수 있다.
Matching for functions with multiple arguments
인수가 여러 개인 경우 C++은 일치하는 규칙을 차례로 각 인수에 적용한다.
그러한 함수가 발견된 경우, 그 함수는 가장 일치하는 함수다.
그러나 그러한 함수를 찾을 수 없는 경우, 호출은 모호함(또는 불일치)으로 간주된다.

위의 프로그램에서 모든 함수는 첫 번째 인수와 정확히 일치한다.
그리고 print(char, int)는 두 번째 매개 변수와 정확히 일치하지만
다른 함수는 변환이 필요하다.
그래서 print(char, int)가 가장 일치하는 함수다.
프로그램을 단순화하려면 함수 오버로딩을 사용하면 된다.
그리고 프로그래밍을 할 때 (함수 오버로딩을 사용할 때) 애초에 명확하게 구현을 하는 것이 좋다.
또한 함수 이름으로 구분을 하는 것이 함수 오버로딩을 억지로 쓰는 것보다 더 좋은 경우도 있다.
그리고 주석을 달아서 ~ 할 때 주의해야 된다 이런 거 꼭 남겨두면 도움이 될 것이다.
리턴타입만으로는 구분이 되지 않는다는 것 기억하기!
경우에 따라서는 매치가 안되서 에러가 날 수도 있고 혹은 매치가 전부 애매해서 에러가 날 수 있다는 점 기억하자.
'💘 C++ > 함수' 카테고리의 다른 글
| 함수 포인터 (Function pointer) (0) | 2022.08.08 |
|---|---|
| 매개변수의 기본값 (Default parameters) (0) | 2022.08.07 |
| 인라인 함수 (Inline Functions) (0) | 2022.07.31 |
| 다양한 반환 값들(값, 주소, 참조, 구조체, 튜플) Returning values (0) | 2022.07.29 |
| 주소에 의한 인수 전달 (Passing Arguments by address(Call by Address)) (2) | 2022.07.27 |



