
스택과 힙 (Stack and Heap) 본문
포인터나 동적 메모리 할당을 공부할 때 좀 더 쉽게 사용할 방법도 있을 것 같은데
왜 이렇게 복잡하게 만들어놨지?라고 궁금해 할 수 있다.
그 의문을 해결하기 위해서는 컴퓨터가 내부에서 CPU가 메모리를 어떻게 사용을 하는지
조금 더 구체적으로 알 필요가 있다.
컴퓨터가 메모리를 사용하는 방법 중 스택과 힙 두 가지 위주로 설명하겠다.

우리가 작성한 프로그램을 컴퓨터에게 실행시켜주세요라고 얘기하면 OS는 메모리를 넘겨준다.
"이 메모리를 가지고 프로그램을 실행시키세요"라고 실행시킬 자리를 마련해주는 것이다.
프로그램이 사용하는 메모리는 일반적으로 Segment 라고 하는 여러 영역으로 나뉘어서 사용된다.
이때 각각의 segment는 역할이 다르다.
Code segment : 우리가 작성한 프로그램이 저장이 된다.
메모리에 올라가 있고 실행시키는 부분을 가져가서 실행을 시키게 된다.
컴파일된 프로그램이 저장되는 영역, 일반적으로 read-only 속성이다.
Data segment 영역에는 두 종류가 있다.
하나는 initialized data segment 다른 하나는 uninitialized data segment이다.
이 Data 영역에는 global variable(전역 변수) 하고 static variable(정적 변수)가 저장된다.
더 자세히 보면
BSS라는 data segment는 uninitialized data segment니까
zero-initialized 0으로 초기화 된 global static variable들이 저장이 된다.
Data segment에는 initialized data segment
그러니까 초기화가 된 전역변수와 정적변수들이 저장이 된다.
프로그램을 실행시킬 때 프로그램 자체가 메모리에 먼저 자리를 잡아야 한다.
그다음으로 오래가는 것이 전역변수이다. 그런 것들은 Data Segment에 저장이 된다.
Stack segment : 함수 매개 변수, 지역 변수 및 기타 함수 관련 정보가 저장된다.
Heap segment : 동적으로 할당된 변수가 할당되는 영역이다.
Stack segment
간단한 프로그램을 하나 만들었다.

전역변수는 g_i를 넣어놨고
OS는 먼저 main 함수를 실행시킨다.
여기 main에서는 local variable인 a와 b가 선언이 되고
그다음에 first라는 함수도 실행을 시킨다.
first라는 함수는 내부에서 다시 second라는 함수를 호출을 하도록 예제를 만들었다.
어떻게 작동되는지 그림으로 보여드리자면
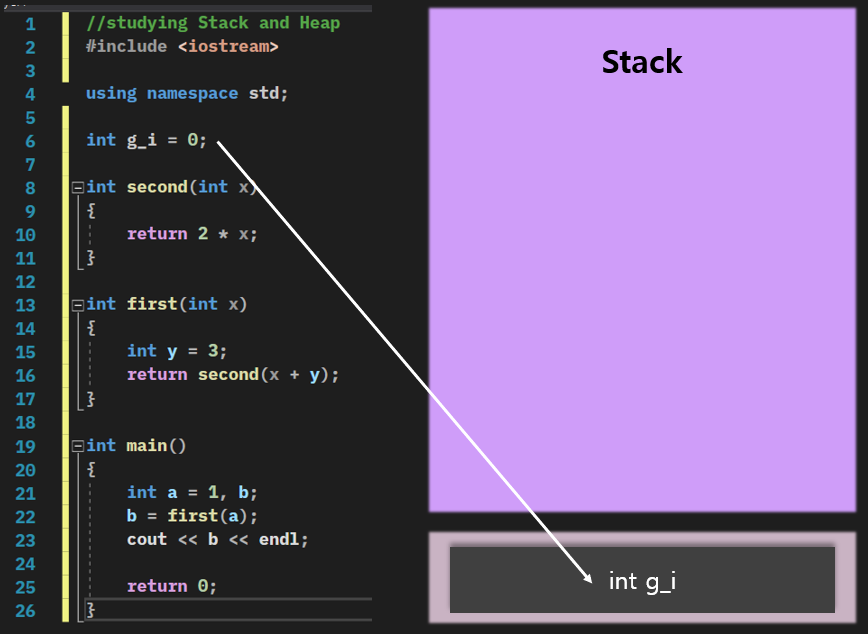

stack은 말 그대로 뭔가 쌓는다는 의미다.
처음에 main 함수가 실행이 되면
stack frame 안에 main함수 자체와
main 함수 안에 있는 local variable인 a와 b가 저장이 된다.
그리고 진행이 쭉 돼가다가
first를 만나게 되면

이런 식으로 first 함수의 stack frame이 또 생겨나서 위에 쌓인다.
그리고 이 frame 안에는 매개변수 x,
그다음 그 안에서 선언이 된 local variable y가 자리 잡는다.
그리고 이 first 함수가 또다시 second 함수를 호출을 한다.

이번에는 매개변수 x가 있고 stack frame 안에 저장이 된다.
second 함수 자체도 stack frame 안에 들어있다.
이 stack frame 안에는 몇 가지 정보가 더 있는데
실행이 끝난 다음에 어디로 돌아가야 되는지도 들어있다.
second 함수가 끝나고 나면
stack에 쌓여있던 것을 위에서부터 제거한다.
쉽게 설명하자면
회전초밥집에 가면 보통 먹은 순서대로 접시를 쌓는다.
그리고 계산하시는 분은 위에서부터 하나씩 치운다.
그렇게 순서를 생각하면 된다.
위에서부터 순서대로 하나씩 사라진다.



그리고 프로그램이 끝나고 OS가 모든 메모리를 걷어가게 된다.
stack은 자료구조 공부를 하면 더 자세하게 배우게 된다.
여기서 알아야 할 것은 stack은 착착 차례대로 쌓여있다는 것과
현재 실행시켜야 하는 것이 가장 위에 있다는 것이다.
그리고 비교적 속도가 조금 빠르다
그래서 local variable들은 사용할 때 좀 더 빠른 속도로 접근을 해서 사용할 수 있다.
물론 local variable 들도 메모리이기 때문에 전부 메모리 주소를 갖는다.
stack segment(= call stack)는 main() 함수부터 현재 실행 지점까지의 모든 활성 함수를 추적하고
모든 함수 매개 변수와 지역 변수의 할당을 처리한다.
스택은 후입선출(LIFO) 자료구조이다.
즉, 가장 늦게 들어간 자료를 가장 먼저 꺼내게 된다.
함수 호출이 끝나고, 이전 함수로 돌아갈 때 이 함수의 바로 이전 함수로 돌아가야 한다.
그래서 컴퓨터는 내부적으로 스택 세그먼트를 스택 자료구조로 구현한다.
call stack이란?
컴퓨터 프로그램에서 현재 실행 중인 서브루틴(함수)에 관한 정보를 저장하는 스택 자료구조이다.
응용프로그램이 시작되면 main() 함수가 OS에 의해 호출 스택에 푸시된다.
그 후 프로그램이 실행되기 시작한다.
함수 호출이 발생하면 함수가 콜 스택에 푸시된다.
현재 함수가 끝나면 해당 함수는 콜 스택에서 해제된다.
따라서 콜 스택에 푸시된 함수를 살펴보면 현재 실행 지점으로 이동하기 위해 호출된 모든 함수를 볼 수 있다.
콜 스택 자체는 고정된 크기의 메모리 영역이다.
여기서 콜 스택에 넣고 빼는 데이터 자체를 stack frame이라고 한다.
stack frame은 하나의 함수 호출과 관련된 모든 데이터를 추적한다.
또한 stack pointer라고 하는 CPU의 작은 조각인 레지스터는 현재 호출 스택의 최상위 위치를 가리킨다.
- The call stack in action
콜 스택이 어떻게 작동하는지 자세히 살펴보자.
함수를 호출할 때 발생하는 단계는 다음과 같다.
- 프로그램에 함수 호출이 발생한다.
- stack frame이 생성되고 call stack에 푸시된다.
stack frame은 다음과 같이 구성된다.
- 함수가 종료되면 복귀할 주소
- 함수의 모든 매개 변수
- 지역 변수
- 함수가 반환할 때 복원해야 하는 수정된 레지스터의 복사본 - CPU가 함수의 시작점으로 점프한다.
- 함수 내부의 명령어를 실행한다.
함수가 종료되면 다음 단계가 수행된다.
- 레지스터가 콜 스택에서 복원된다.
- stack frame이 call stack에서 튀어나온다.
이렇게 하면 모든 지역 변수와 매개 변수에 대한 메모리가 해제된다. - 반환 값이 처리된다.
- CPU는 반환 주소에서 실행을 재개한다.
반환 값은 시스템 아키텍처에 따라 여러 가지 방법으로 처리한다.
반환 값이 stack frame의 일부로 포함되기도 하며, CPU 레지스터를 사용하기도 한다.
일반적으로 콜 스택이 어떻게 동작하는지에 대한 모든 세부 사항은 중요하지 않다.
그러나 함수가 호출될 때와 종료될 때 함수가 콜 스택에서 효과적으로 작동한다는 것을 이해하면
재귀를 이해할 때와 디버깅할 때 유용하다.
Stack Overflow
stack은 단점이 있다.
위에서 말했듯이 좀 빠르다.
빠르고 좋은 것은 보통 크기가 작다.
stack의 단점은 사이즈가 좀 작다.

위 코드를 실행시키면 array가 너무 커서 메모리 할당을 못한다.
stack에 거대한 크기의 배열을 할당하려고 시도한다.

그러나 stack segment 크기가 배열을 처리할 만큼 충분히 크지 않으므로
배열 할당은 응용 프로그램에서 사용할 수 없는 메모리 부분까지 오버플로우 된다.
따라서 프로그램이 다운된다.
이런 것을 stack overflow라고 부른다.
이렇게 큰 것을 한 번에 잡아서 넘쳐나는 경우도 있지만
자잘한 것들을 여러 번 호출해서 넘쳐나는 경우도 있다.
그 대표적인 사례는 곧 포스팅할 재귀 호출 같은 것이 있다
재귀 호출같은 경우에는 너무 많이 함수가 함수를 부르게 되는 경우
stack에 착착 쌓여가다가 어느 순간 stack을 넘쳐나면서 오류가 생긴다.
이 내용은 추후 다시 설명드리겠다.
Stack segment는 크기가 제한되어 있으므로 제한된 양의 데이터만 저장할 수 있다.
window 운영체제에서 기본 스택 세그먼트의 크기는 1MB이다.
응용프로그램이 stack segment에 너무 많은 정보를 넣으려고 하면 stack overflow가 발생한다.
stack overflow는 stack segment의 모든 메모리가 할당되어 꽉 찼을 때 발생하며,
이 경우 추가 할당이 메모리의 다른 섹션으로 넘치기 시작한다.
Stack overflow는 일반적으로 stack segment에 너무 많은 변수를 할당하거나 중첩된 함수 호출을 너무 많이 한 결과다.
- stack에 메모리를 할당하는 것은 비교적 빠르다.
- stack에 할당된 메모리는 stack 범위에 있을 때만 접근할 수 있다.
- stack에 할당된 모든 메모리는 컴파일 타임에 알려진다.
메모리는 변수를 통해 직접 접근할 수 있다. - stack은 비교적 크기가 작으므로 stack 공간을 많이 차지하는 지역 변수를 만드는 것은 좋지 않다.
Heap Segment
Heap Segment는 동적 메모리 할당에 사용되는 메모리를 추적한다.
C++에서 new연산자를 사용해서 메모리를 할당하면 이 메모리는 응용 프로그램의 Heap Segment에 할당된다.
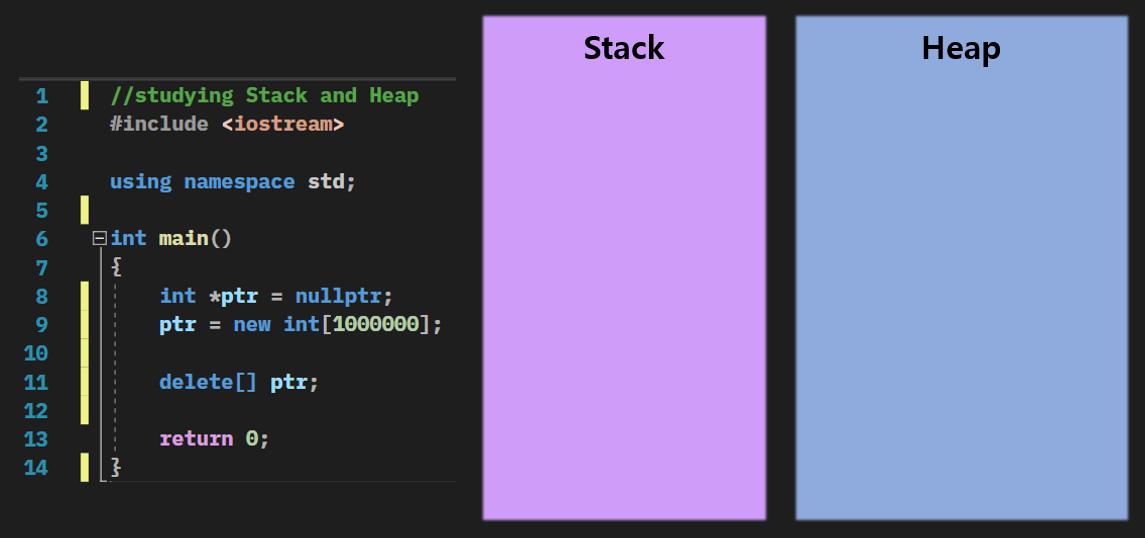
지역 변수들은 stack에 저장이 되고 비교적 빠른 대신에 사이즈가 작다.
그래서 stackoverflow 같은 문제가 생길 수 있다고 말씀드렸다.
대신에 이것을 보완해주기 위해서 Heap 메모리를 추가로 사용한다.
참고로 ‘힙 메모리’의 ‘힙’은 힙 자료구조와는 상관이 없다.
어떻게 진행되는지 한번 보자.

먼저 main 함수가 실행이 되고
포인터 변수가 stack에 들어오게 된다.
포인터도 변수라고 자꾸 말씀드린 이유가 포인터 변수도 결국은 변수!
즉, 주소라는 값을 저장하는 공간에 불과하다고 말씀드린 적 있다.
그리고 다음 줄에서 동적 메모리가 할당이 되면

Heap에 int [1000000] 사이즈만큼의 메모리가 잡힌다.
Heap은 사이즈가 크다.
그래서 큰 데이터를 넣을 수 있는 공간을 마음껏 확보할 수 있다.
대신 단점은 얘가 어디에 생길지 예측을 하기 힘들다.
stack은 착착 쌓이기 때문에 얘가 다음에 어디쯤 오겠구나 미리 예측할 수 있는 경향이 있다.
하지만 Heap은 사이즈가 큰 대신 메모리가 어디에 들어올지 알기 쉽지 않다.
여러 가지 이유가 있는데 큰 데이터를 집어넣는다고 가정하면
그 데이터가 일렬로 들어갈 수 있는 공간을 마련해야 한다.
분할해서 집어넣을 수가 없는 구조일 경우에는
이 큰 데이터가 한꺼번에 들어갈 곳을 찾아야 한다.
OS가 "내가 봤을 땐 여기에 넣는 게 가장 좋아 보여요" 하면서 가장 적당한 곳을 지정을 하고
그 메모리 공간의 첫 주소를 포인터에 저장을 해주게 되는 것이다.

마지막으로 delete으로 지우고 있다.
delete로 지우게 되면 OS에 "이 주소에 있던 메모리 더는 안 써요 도로 가져가세요"라고 한다.
그리고 지금 위 예제에서는 뒤에 더 이상의 코드가 없이 끝나니까 ptr이 아무런 문제가 없다.
하지만 여기서 주의해야 할 것은
Heap에 있는 메모리 자체는 OS로 반납이 되었지만
ptr은 아직 어떤 주소를 값으로 가지고 있다.
그러니까 만약 코드 뒤에서 ptr을 이용해서 de-referencing을 하면
Heap에 가봤는데 이미 OS가 가져가서 다른 데에 쓰고 있다고 하면 뭘 할 수가 없게 되니까 문제가 생긴다.
그래서 만약 이 코드가 여기서 끝나는 게 아니고

delete 한 후에 더 사용을 해야 한다면
nullptr로 assignment 해주고
프로그래밍할 때도 여러 가지 주의를 기울여서 코딩하면
문제가 생기는 것을 방지할 수 있다.
다른 사례를 보자.

main 함수가 있고
initArray라는 함수가 있고
initArray 함수에서는 동적 할당을 하고 있다.
그런데 delete를 안 할 경우에 어떤 일이 벌어지는지 보자.

initArray 함수가 실행이 되었고
그다음에 new int 하면서 Heap에 메모리를 잡았다.
Heap에는 메모리가 잡혀있고
OS가 "아 이 메모리는 이 프로그램이 쓰는 거구나. 안 건드릴게 편한 대로 써라"라고 해서 잡혀있는 상황이다.
그리고 ptr2라는 포인터 변수는 이 Heap안에 잡혀있는 메모리의 첫 주소를 가지고 있는다.
그래서 언제든지 접근할 수가 있다.
그런데 문제는 initArray함수가 끝나고 나가버리는데

delete을 안 했다
그러니까 주소를 적어놓은 ptr2가 사라져 버린 것이다.
위 프로그램은 Heap에 메모리를 가지고는 있지만 어디 있는지 알 방법이 없다.
그래서 사용할 수가 없다.
이런 일이 반복이 되면 Heap 메모리도 쓸 수 없는 메모리로 가득 차서 문제가 생긴다.
꽉 차는 것도 문제지만 작은 메모리라도 이런 식으로 메모리 누수가 반복이 되면
다른 프로그램이 사용할 메모리를 잠식해버린다.
그래서 큰 문제가 생긴다.
메모리 누수도 주의할 필요가 있다.
Heap Segment는 동적 메모리 할당에 사용되는 메모리를 추적한다.
C++에서 new 연산자를 사용해서 메모리를 할당하면 이 메모리는 응용 프로그램의 Heap segment에 할당된다.
Heap에는 장단점이 있다.
- Heap에 메모리를 할당하는 것은 비교적 느리다.
- 할당된 메모리는 명시적으로 할당 해제하거나 응용 프로그램이 종료될 때까지 유지된다. (메모리 leak 주의)
- 동적으로 할당된 메모리는 포인터를 통해 접근한다.
포인터를 역참조하는 것은 변수에 직접 접근하는 것보다 느리다. - Heap은 큰 메모리 풀이므로 큰 배열, 구조체 또는 클래스를 할당할 수 있다.
'💘 C++ > 함수' 카테고리의 다른 글
| 재귀적 함수 호출 (Recursive Function Call) (0) | 2022.08.18 |
|---|---|
| std::vector를 stack처럼 사용하기 (0) | 2022.08.17 |
| 함수 포인터 (Function pointer) (0) | 2022.08.08 |
| 매개변수의 기본값 (Default parameters) (0) | 2022.08.07 |
| 함수 오버로딩 (Function Overloading) (0) | 2022.08.06 |



